
Last Updated: October 28, 2025
Introduction to Nucleic Acids
As a class, the nucleic acids (nucleotides) may be considered one of the most important nitrogenous metabolites of the cell. Nucleotides are found primarily as the monomeric units comprising the major nucleic acids of the cell, RNA and DNA. However, they also are required for numerous other important functions within the cell. These functions include:
1. Serving as energy stores for future use in phosphate transfer reactions. These reactions are predominantly carried out by ATP.
2. Forming a portion of several important coenzymes such as NAD+, NADP+, FAD and coenzyme A.
3. Serving as mediators of numerous important cellular processes such as second messengers in signal transduction events. The predominant second messenger is cyclic-AMP (cAMP), a cyclic derivative of AMP formed from ATP.
4. Serving as neurotransmitters and as signal receptor ligands. Adenosine can function as an inhibitory neurotransmitter, while ATP also affects synaptic neurotransmission throughout the central and peripheral nervous systems. ADP is an important activator of platelet functions resulting in control of blood coagulation.
5. Controlling numerous enzymatic reactions through allosteric effects on enzyme activity.
6. Serving as activated intermediates in numerous biosynthetic reactions. These activated intermediates include S-adenosylmethionine (S-AdoMet or SAM) involved in methyl transfer reactions as well as the many sugar coupled nucleotides involved in glycogen and glycoprotein synthesis.
Nucleoside and Nucleotide Structure and Nomenclature
The nucleotides found in cells are derivatives of the heterocyclic highly basic, compounds, purine and pyrimidine.
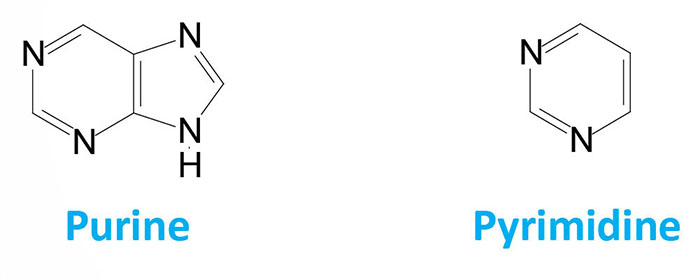
It is the chemical basicity of the nucleotides that has given them the common term “bases” as they are associated with nucleotides present in DNA and RNA. There are five major bases found in cells. The derivatives of purine are called adenine and guanine, and the derivatives of pyrimidine are called thymine, cytosine and uracil. The common abbreviations used for these five bases are, A, G, T, C and U.
| Base Formula | Base (X=H) | Nucleoside X=ribose or deoxyribose | Nucleotide X=ribose phosphate |
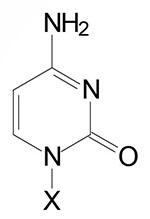 | Cytosine, C | Cytidine, C | Cytidine monophosphate, CMP |
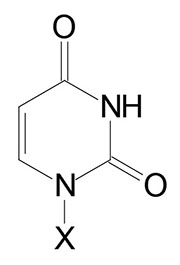 | Uracil, U | Uridine, U | Uridine monophosphate, UMP |
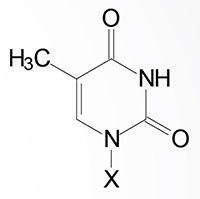 | Thymine, T | Thymidine, T (only deoxyribose) | Thymidine monophosphate, TMP |
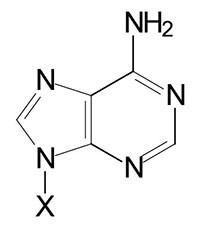 | Adenine, A | Adenosine, A | Adenosine monophosphate, AMP |
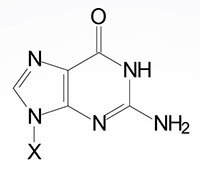 | Guanine, G | Guanosine, G | Guanosine monophosphate, GMP |
The purine and pyrimidine bases in cells are linked to carbohydrate and in this form are termed, nucleosides. The nucleosides are coupled to D-ribose or 2′-deoxy-D-ribose through a β-N-glycosidic bond between the anomeric carbon of the ribose and the N9 of a purine or N1 of a pyrimidine.
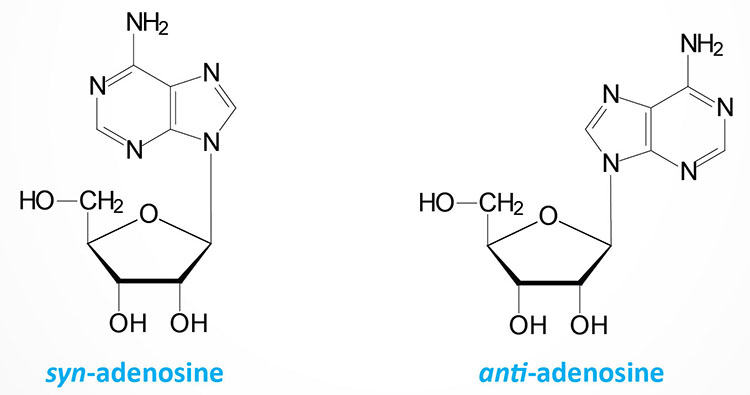
The base can exist in two distinct orientations about the N-glycosidic bond. These conformations are identified as, syn and anti. It is the anti conformation that predominates in naturally occurring nucleotides.
Nucleosides are found in the cell primarily in their phosphorylated form. These are termed nucleotides. The most common site of phosphorylation of nucleotides found in cells is the hydroxyl group attached to the 5′-carbon of the ribose. The carbon atoms of the ribose present in nucleotides are designated with a prime (‘) mark to distinguish them from the backbone numbering in the bases. Nucleotides can exist in the mono-, di-, or tri-phosphorylated forms.
Nucleotides are given distinct abbreviations to allow easy identification of their structure and state of phosphorylation. The monophosphorylated form of adenosine (adenosine-5′-monophosphate) is written as, AMP. The di- and tri-phosphorylated forms are written as, ADP and ATP, respectively. The use of these abbreviations assumes that the nucleotide is in the 5′-phosphorylated form. The di- and tri-phosphates of nucleotides are linked by acid anhydride bonds. Acid anhydride bonds have a high ΔG0′ for hydrolysis imparting upon them a high potential to transfer the phosphates to other molecules. It is this property of the nucleotides that results in their involvement in group transfer reactions in the cell.
The nucleotides found in DNA are unique from those of RNA in that the ribose exists in the 2′-deoxy form and the abbreviations of the nucleotides contain a “d” designation. The monophosphorylated form of adenosine found in DNA (deoxyadenosine-5′-monophosphate) is written as dAMP.
The nucleotide uridine is never found naturally occurring in DNA and thymine is almost exclusively found in DNA. Thymine is found in tRNAs but not rRNAs nor mRNAs. There are several less common bases found in DNA and RNA. The primary modified base in DNA is 5-methylcytosine. A variety of modified bases appear in the tRNAs. Many modified nucleotides are encountered outside of the context of DNA and RNA that serve important biological functions.
Adenosine Derivatives
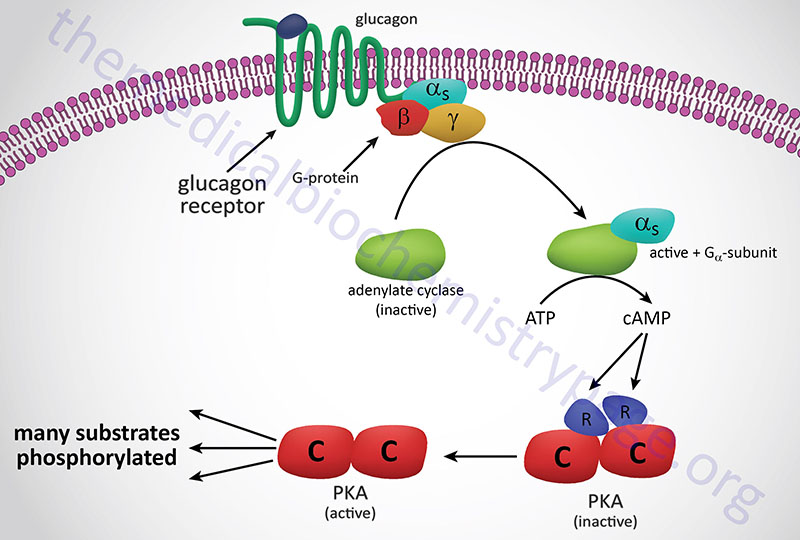
The most common adenosine derivative is the cyclic form, 3′-5′-cyclic adenosine monophosphate, cAMP. This compound is a very powerful second messenger involved in passing signal transduction events from the cell surface to internal proteins such as the serine/threonine (Ser/Thr) kinase, cAMP-dependent protein kinase, PKA (see Figure below). PKA phosphorylates a number of proteins, thereby, affecting their activity either positively or negatively. Cyclic-AMP is also involved in the regulation of ion channels by direct interaction with the channel proteins, e.g. in the activation of odorant receptors by odorant molecules and in the regulation of Ca2+ channels in the plasma membranes of smooth muscle cells and several other cell type.
Formation of cAMP occurs in response to activation of receptor coupled adenylate cyclase. Receptors for certain peptide hormones, as well as the odorant receptors, are members of the large family of G-protein coupled receptors (GPCR). The GPCR members that activate adenylate cyclase are coupled to GTP binding and hydrolyzing heterotrimeric G-proteins of the Gs type.
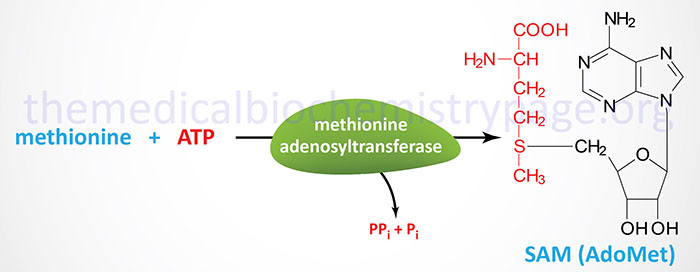
S-adenosylmethionine is a form of activated methionine which serves as a methyl donor in numerous critical methylation reactions and as a source of propylamine in the synthesis of polyamines.
Guanosine Derivatives
A cyclic form of GMP (cGMP) also is found in cells and like cAMP functions as a second messenger molecule. In many cases its role is to antagonize the effects of cAMP. Formation of cGMP occurs in response to receptor mediated signals similar to those for activation of adenylate cyclase. However, in this case it is guanylate cyclase that is coupled to the receptor or as in the case of the atrial natriuretic peptide (ANP or atrial natriuretic factor, ANF) receptor, the receptor itself has intrinsic guanylate cyclase activity. Additional effects of cGMP include the regulation of ion channels and the activity of certain types of phosphodiesterases.
The formation of cGMP, and its subsequent activation of cGMP-dependent protein kinase (PKG), plays a critical role in the regulation of blood pressure. Like PKA, PKG is a heterotetramer composed of two regulatory and two catalytic subunits and cGMP binds to the regulatory subunits leading to the release of the catalytic subunits. Within the vasculature, either nitric oxide (NO) or ANP signaling activates the production of cGMP leading to activation of PKG. The activated PKG then phosphorylates several proteins (e.g. vasodilator-stimulated phosphoprotein, VASP) resulting in relaxation of smooth muscle cells.
One of the most important cGMP coupled signal transduction cascades is that involved in photoreception. However, in this case activation of rhodopsin (in the rods) or other opsins (in the cones) by the absorption of a photon of light (through 11-cis-retinal covalently associated with rhodopsin and opsins) activates transducin which in turn activates a cGMP specific phosphodiesterase that hydrolyzes cGMP to GMP. This lowers the effective concentration of cGMP bound to gated ion channels resulting in their closure and a concomitant hyperpolarization of the cell.
Nucleotide Derivatives in RNAs
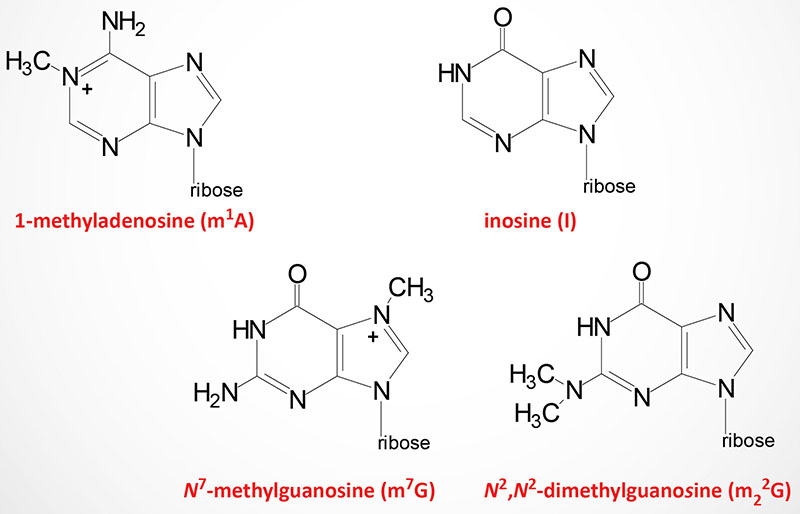
Modified nucleotides are found in all three classes of RNA: tRNA, rRNA, and mRNA. As many as 25% of the nucleotides found in tRNAs (go to the Protein Synthesis (Translation): Processes and Regulation page for discussion of tRNAs and translation) are modified post-transcriptionally. At least 80 different modified nucleotides have been identified at >60 different positions in various tRNAs.
The two most commonly occurring modified nucleotides in tRNA are dihydrouridine (abbreviated D) and pseudouridine (designated with the Greek capital Psi: Ψ) each of which is found in a characteristic loop structure in tRNAs.
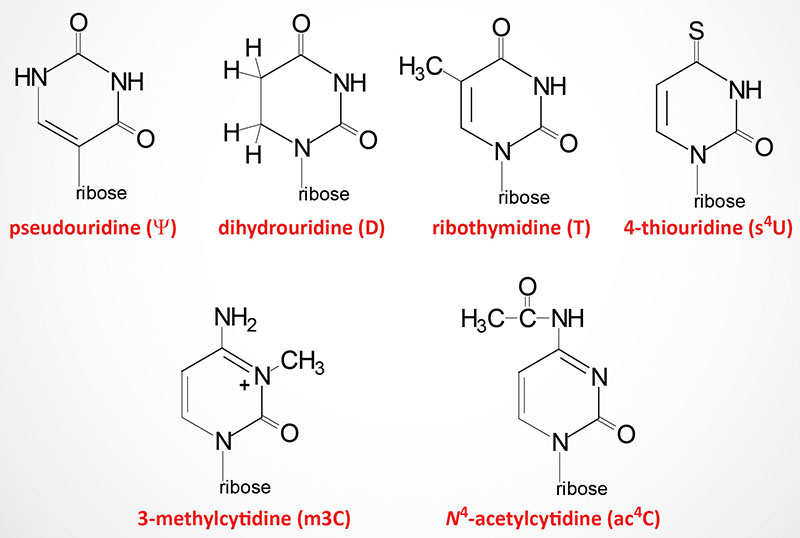
Dihydrouridine is found in the D-loop (hence the name of the loop) and pseudouridine is found in the TΨC loop (hence the name of the loop).
Pseudouridine is the 5-ribosyl isomer of uridine that is generated a 180 degree rotation of the uridine base such that the base is attached to the 1′ carbon of the ribose via a carbon-carbon glycosidic bond instead of the normal nitrogen-carbon glycosidic bond. In addition to its presence in tRNA, pseudouridine is found in both rRNA and mRNA but at a much lower level compared to that in tRNA. A particularly significant pseudouridine in rRNA is a highly conserved modification found in the A-site of the ribosome. If this pseudouridine is lost or fails to be produced due to mutations in the proteins encoding the pseudouridylation complex, the binding of aminoacyl-tRNAs to the A-site is lost and translation fails.
In addition to pseudouridine, mRNAs contain modified adenosines and cytosines, N6-methyladenosine (m6A) and N5-methylcytosine (m5C), respectively. The mechanism for mRNA nucleotide modification and the functional significances are discussed in greater detail in the RNA: Transcription and Processing page.
Synthetic Nucleotide Analogs
Many nucleotide analogues are chemically synthesized and used for their therapeutic potential. The nucleotide analogues can be utilized to inhibit specific enzymatic activities. A large family of analogues are used as anti-tumor agents, for instance, because they interfere with the synthesis of DNA and thereby preferentially kill rapidly dividing cells such as tumor cells. Some of the nucleotide analogues commonly used in chemotherapy are 6-mercaptopurine, 5-fluorouracil, 5-iodo-2′-deoxyuridine and 6-thioguanine. Each of these compounds disrupts the normal replication process by interfering with the formation of correct Watson-Crick base-pairing. Nucleotide analogs also have been targeted for use as antiviral agents. Several analogs are used to interfere with the replication of HIV, such as AZT (azidothymidine) and ddI (dideoxyinosine).
Several purine analogs are used to treat gout, one of the most common being allopurinol, which resembles hypoxanthine. Allopurinol inhibits the activity of xanthine oxidase, an enzyme involved in purine nucleotide catabolism. Additionally, several nucleotide analogues are used after organ transplantation in order to suppress the immune system and reduce the likelihood of transplant rejection by the recipient.
Polynucleotides
Polynucleotides are formed by the condensation of two or more nucleotides. The condensation most commonly occurs between the alcohol of a 5′-phosphate of one nucleotide and the 3′-hydroxyl of a second, with the elimination of H2O, forming a phosphodiester bond. The formation of phosphodiester bonds in DNA and RNA exhibits directionality. The primary structure of DNA and RNA (the linear arrangement of the nucleotides) proceeds in the 5′ → 3′ direction. The common representation of the primary structure of DNA or RNA molecules is to write the nucleotide sequences from left to right synonymous with the 5′ → 3′ direction as shown:
5’–pGpApTpC–3′
Structure of DNA
Utilizing X-ray diffraction data, obtained from crystals of DNA, James Watson and Francis Crick proposed a model for the structure of DNA. This model (subsequently verified by additional data) predicted that DNA would exist as a helix of two complementary antiparallel strands, wound around each other in a rightward direction and stabilized by H-bonding between bases in adjacent strands. In the Watson-Crick model, the bases are in the interior of the helix aligned at a nearly 90 degree angle relative to the axis of the helix. Purine bases form hydrogen bonds with pyrimidines, in the crucial phenomenon of base pairing. Experimental determination has shown that, in any given molecule of DNA, the concentration of adenine (A) is equal to thymine (T) and the concentration of cytidine (C) is equal to guanine (G). This means that A will only base-pair with T, and C with G. According to this pattern, known as Watson-Crick base-pairing, the base-pairs composed of G and C contain three H-bonds, whereas those of A and T contain two H-bonds. This makes G–C base-pairs more stable than A–T base-pairs.
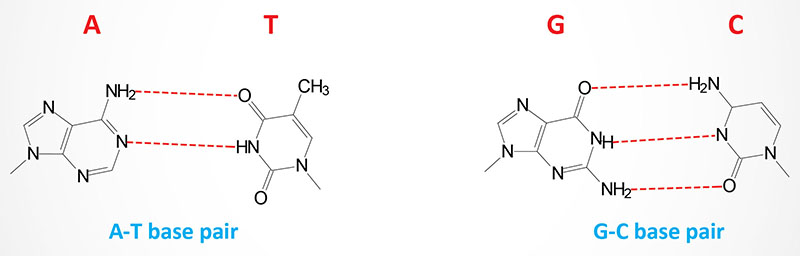
The antiparallel nature of the helix stems from the orientation of the individual strands. From any fixed position in the helix, one strand is oriented in the 5′ → 3′ direction and the other in the 3′ → 5′ direction. On its exterior surface, the double helix of DNA contains two deep grooves between the ribose-phosphate chains. These two grooves are of unequal size and termed the major and minor grooves. The difference in their size is due to the asymmetry of the deoxyribose rings and the structurally distinct nature of the upper surface of a base-pair relative to the bottom surface.
The double helix of DNA has been shown to exist in several different forms, depending upon sequence content and ionic conditions of crystal preparation. The B-form of DNA prevails under physiological conditions of low ionic strength and a high degree of hydration. Regions of the helix that are rich in pCpG dinucleotides can exist in a novel left-handed helical conformation termed Z-DNA. This conformation results from a 180 degree change in the orientation of the bases relative to that of the more common A- and B-DNA.
Table of the Physical Characteristics of Major DNA Helices
| Parameters | A Form | B Form | Z-Form |
| Direction of helical rotation | Right | Right | Left |
| Residues per turn of helix | 11 | 10 | 12 base pairs |
| Rotation of helix per residue (in degrees) | 33 | 36 | -30 |
| Base tilt relative to helix axis (in degrees) | 20 | 6 | 7 |
| Major groove | narrow and deep | wide and deep | Flat |
| Minor groove | wide and shallow | narrow and deep | narrow and deep |
| Orientation of N-glycosidic bond | anti | anti | anti for Pyrimidines, syn for Purines |
| Comments | most prevalent within cells | occurs in stretches of alternating purine-pyrimidine base pairs |
Thermal Properties of DNA
As cells divide it is a necessity that the DNA be copied (replicated), in such a way that each daughter cell acquires the same amount of genetic material. In order for this process to proceed the two strands of the helix must first be separated, in a process termed denaturation. This process can also be carried out in vitro. If a solution of DNA is subjected to high temperature, the H-bonds between bases become unstable and the strands of the helix separate in a process of thermal denaturation.
The base composition of DNA varies widely from molecule to molecule and even within different regions of the same molecule. Regions of the duplex that have predominantly A-T base-pairs will be less thermally stable than those rich in G-C base-pairs. In the process of thermal denaturation, a point is reached at which 50% of the DNA molecule exists as single strands. This point is the melting temperature (Tm), and is characteristic of the base composition of that DNA molecule. The Tm depends upon several factors in addition to the base composition. These include the chemical nature of the solvent and the identities and concentrations of ions in the solution.
When thermally melted DNA is cooled, the complementary strands will again re-form the correct base pairs, in a process is termed annealing or hybridization. The rate of annealing is dependent upon the nucleotide sequence of the two strands of DNA.
Analysis of DNA Structure
Chromatography: Several of the chromatographic techniques available for the characterization of proteins can also be applied to the characterization of DNA. The most commonly used technique is HPLC (high performance liquid chromatography). Affinity chromatographic techniques also can be employed. One common affinity matrix is hydroxylapatite [a form of calcium phosphate: Ca5(PO4)3(OH)], which binds double-stranded DNA with a higher affinity than single-stranded DNA.
Electrophoresis: This procedure can serve the same function with regard to DNA molecules as it does for the analysis of proteins. However, since DNA molecules have much higher molecular weights than proteins, the molecular sieve used in electrophoresis of DNA must be different as well. The material of choice is agarose, a carbohydrate polymer purified from a salt water algae. It is a copolymer of mannose and galactose that when melted and re-cooled forms a gel with pores sizes dependent upon the concentration of agarose. The phosphate backbone of DNA is highly negatively charged, therefore DNA will migrate in an electric field. The size of DNA fragments can then be determined by comparing their migration in the gel to known size standards. Extremely large molecules of DNA (in the range of 30kb–10Mb) are effectively separated in agarose gels using pulsed-field gel electrophoresis (PFGE). This technique employs two or more electrodes, placed orthogonally with respect to the gel, that receive short alternating pulses of current. PFGE allows whole chromosomes and large portions of chromosomes to be analyzed.